The process for creating Azure Functions is straightforward on the Azure Portal. The only confusing option you have to consider during the function creation is which hosting model to choose from the available choices. There are four different hosting plans to choose from, where you will also be able to determine which OS to host your functions. In this blog post, I’ll have a review of different choices and what suits you best. This is what you will see on Azure Portal when choosing your hosting plan:
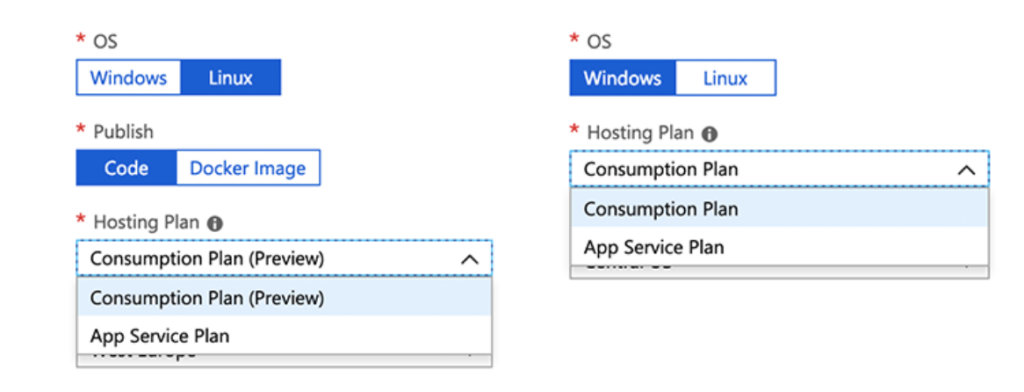
Consumption plan
Consumption plan is open on both Windows and Linux plans (Linux currently in the public preview). If you are new to the Azure Functions or need the function just up and running, I would recommend picking this plan, as it will make your life easier and you can get to the coding part rapidly. With this option, the function will dynamically allocate enough compute power or in other words, hosts to run your code and scale up or down automatically as needed. You will pay only for the use and not when for idle time. The bill is based aggregated from all functions within an app on the number of executions, execution time and memory used.
App Service Plan
App Service Plan is the second choice both available on Windows and Linux OS. This plan will dedicate you a virtual machine to run your functions. If you have long-running, continuous, CPU and memory consumable algorithms, this is the option you want to choose to have the most cost-effective hosting plan for the function operation. This plan makes it available to choose from Basic, Standard, Premium, and Isolated SKUs application plans and also connect to your on-premises VNET/VPN networks to communicate with your site data. In this plan, the function will not consume any more than the cost of the VM instance that is allocated. Azure App Service Plans can be found from Microsoft’s official documentation.
An excellent example for choosing the App Service Plan is when the system needs continuously crawl for certain data from on-premises or the internet and save the information to Azure Blob Storage for further processing.
Containers
Azure Functions also supports having custom Linux images and containers. I’ll dedicate a blog post for that option shortly.
Timeouts
The function app timeout duration for Consumption plan by default is five minutes and can be increased to ten minutes in both version one and two. For the App Service plan version one has an unlimited timeout by default but the time out for version two of functions is 30 minutes which can be scaled to unlimited if needed.
After creating the function with a particular hosting plan, you cannot change it afterwards, and the only way is to recreate the Function App. The current hosting plan on the Azure Portal is available under the Overview tab when clicking on the function name. More information about pricing can be found from the Azure functions pricing page.